告别new时代!揭秘复制对象高效技巧,性能提升翻倍秘诀
在Java中,创建对象通常使用`new`关键字。然而,频繁地使用`new`可能会对性能产生影响,尤其是在创建大量对象时。为了提高性能,可以考虑使用对象池、原型模式或不可变对象等技术。下面将介绍一些复制对象的神秘技巧,以帮助你提升性能。
### 1. 对象池(Object Pool)
对象池是一种设计模式,用于管理一组可重用的对象。通过重用对象,可以减少创建和销毁对象的开销。以下是一个简单的对象池示例:
```java
import java.util.concurrent.ConcurrentLinkedQueue;
public class ObjectPool
public ObjectPool(int poolSize, Factory
public T borrowObject() {
return pool.poll();
}
public void returnObject(T object) {
pool.offer(object);
}
public interface Factory
使用对象池的示例:
```java
public class MyObject {
// 对象的属性和方法
}
public class MyObjectFactory implements ObjectPool.Factory
public class Main {
public static void main(String
相关内容:
复制功能的响应从两秒降到了百分之一秒,产品经理当场愣住。第二天早上他把那条需求又翻出来看了两遍,确认没看错。
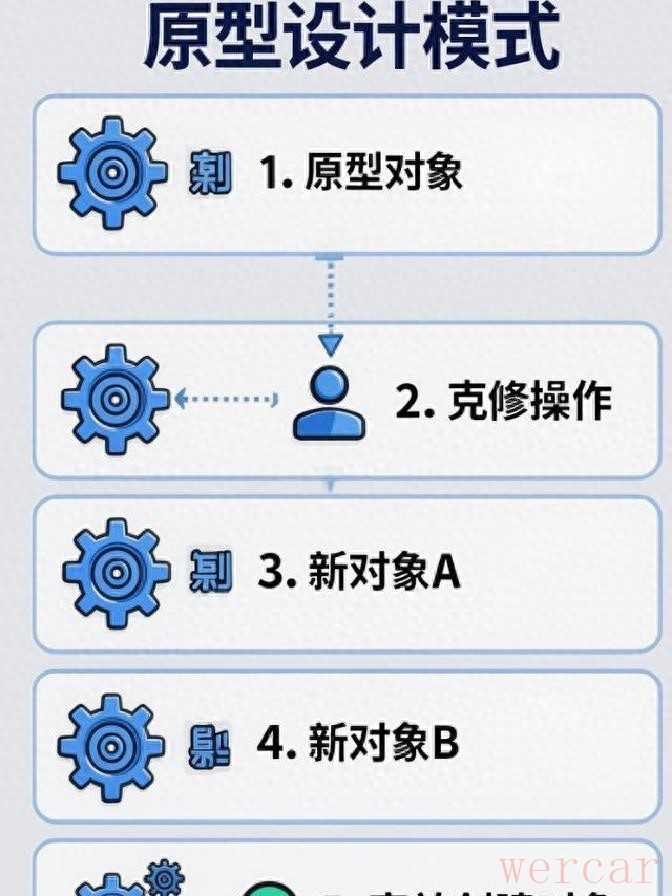
我是这么把事情倒回去说清楚的。周三下午,产品经理丢了个需求过来:下单时要复制购物车内容,但优惠券和地址不能原封不动,要让用户重新选择。乍一听很小的改动,接手后就开始写复制逻辑。我一开始把每个字段都写成setter一项项复制,想着稳妥。到了第十五个setter,我停下了——这活儿写不完,而且很脆弱。
写一堆setter的问题不只是码字多。每次new一个订单对象,都要走一圈初始化,很多对象短时间内被创建,内存占用和垃圾回收频繁,CPU也跟着吃力。再有,如果Order类稍微改一下,所有那些手工复制的地方都要去改。那一刻代码感觉像堆炸药,一碰就麻烦。那天晚上,我一直盯着屏幕,喝到第四杯咖啡,直到凌晨三点才想到书里提过的一个办法——把对象克隆一份,而不是重新造一个。

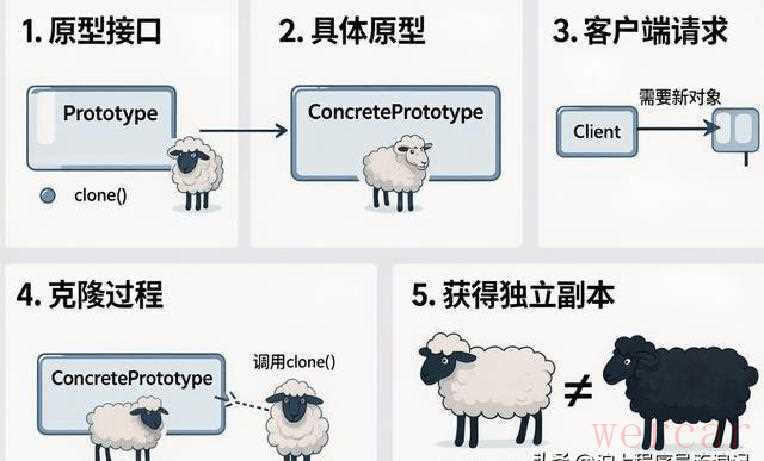
用克隆代替新建,思路很直接:把基准对象复制一份,保留不变的部分,变动的字段再单独处理。像细胞分裂那样,把已有的结构直接复制过去,比从头拼装要快很多。实践里,就是先实现一个clone逻辑,把Order大部分字段浅拷贝过来,然后把优惠券和地址这些必须重新选择的字段清空或重置成默认,购物车items则根据需要做深拷贝。
这里要提醒两件容易被忽视的事。第一,默认的clone通常是浅拷贝。items是List的话,原来的列表和新订单会指向同一个List对象,谁改了东西另一个也跟着变。第二,复制操作并不意味着所有成员都该一视同仁地直接复制,有些字段适合共享,有些必须独立。具体判断要看字段的语义:可变集合一般要深拷,人不可变的元数据可以复用。
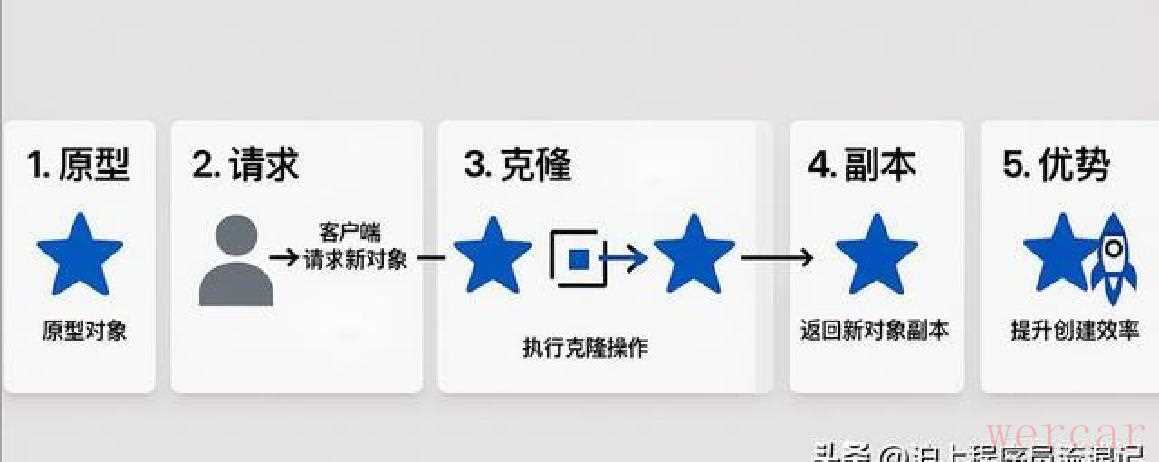
我把旧的复制点都替换成以原型为基础的复制函数。步骤很简单但要注意顺序:先从一个标准的订单实例浅拷贝出壳体,然后针对每个需要独立的集合做新的实例化并逐个复制元素(元素本身如果有可变状态也得处理),最后把优惠券、地址置空或设为待选状态。改完后跑了几轮单元测试,模拟高并发下的下单场景,对比数据就出来了:原来复制功能响应平均要两秒左右,现在大概在一百毫秒以内。内存分配和GC次数明显下降,CPU占用也少了不少,整个复制流程变得稳当又快。
再说说判断要不要用原型的直观信号。代码里如果出现大量手工复制字段的场景;复制逻辑散落在项目各处且容易被遗漏;还有就是频繁new对象导致性能瓶颈,这三种情况时,你可能需要考虑克隆或原型方式。碰到这些就别再硬写setter了,先想想是否能把复制规则集中到一处,用克隆为基础再做必要的调整。
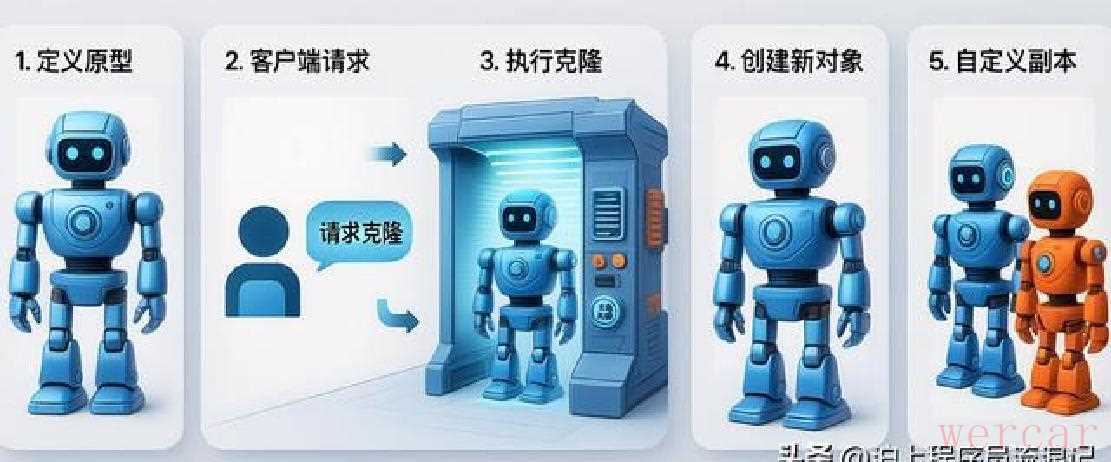
实施中也有坑。最常见的就是“共享集合”的问题:一个订单的商品列表如果直接复用,修改一边另一个也变,会导致奇怪的订单串台。解决办法是对集合做新实例,并递归地复制每个元素,或者把元素做成不可变对象。另一个坑在于对象图复杂时,深拷贝会变得难以维护,这时需要权衡哪些字段可共享,哪些必须独立,避免盲目地把全部对象都深拷一遍,反而带来性能和维护负担。
当晚加班到三点的那段经历让我有点懊恼,一方面是因为自己在常见设计模式上反应慢,另一方面也觉得先前写的那些冗余代码完全可以避免。从工程角度看,原型思路让复制逻辑更集中,变更耦合更小,性能也得到了实实在在的提升。产品经理第二天的反应说明这次改动确实解决了痛点,他当时还提了个小建议:把标准订单样例放到测试库里,方便以后做基准。
如果你想试试,我把练习代码放在了库里,按需自取。换句话说,这事儿没那么复杂:先观察代码里是否有复制的重复劳动,再看性能指标是不是被对象创建拖慢,按需把复制逻辑搬成基于原型的实现。你在项目里遇到过类似的“浅拷贝陷阱”吗?留言说说你那次栽跟头的细节吧。